ISSN 1666-7948
www.quimicaviva.qb.fcen.uba.ar
|
ISSN 1666-7948 www.quimicaviva.qb.fcen.uba.ar |
por
Juan Carlos Calvo
Dr. en Ciencias Químicas, Facultad de Ciencias Exactas y Naturales, Universidad de Buenos Aires. Profesor Adjunto del Departamento de Química Biológica, FCEyN, UBA. Investigador Independiente, CONICET. Director del Departamento de Química Biológica, FCEyN, UBA.
El
otro día, mientras viajaba en subte, observé a una persona, probablemente un
profesor o maestro, corrigiendo lo que parecía ser una composición cuyo tema
era “Zapatillas a medida”. En ese momento, se me ocurrió el título para
este comentario: “Proteínas a medida”.
Evidentemente,
la gran variedad de seres humanos hace necesaria la existencia de productos
hechos “a medida”: trajes, vestidos, zapatillas, etc.
Y
esto cumple la función de cubrir las necesidades de cada individuo, haciendo la
vida más confortable.
Y
esto no es algo nuevo. Desde que el hombre se irguió sobre sus pies y observó
a su alrededor, encontró animales y vegetales para su consumo, y también, para
que lo ayudaran en su trabajo, por ejemplo: como animales de tiro.
Y esto le trajo bienestar, tanto a él como a sus vecinos. Pero, el
avance trajo consigo nuevas necesidades, algunas vitales y otras que tenían que
ver con deseos de progresar y estar mejor.
Con esto surge la Biotecnología, el uso de organismos biológicos o sus
componentes, para el desarrollo de productos o la prestación de servicios. Y,
así, combinó especies vegetales obteniendo especies híbridas con características
particulares: resistencia a las heladas, a plagas, mejor sabor, aspecto, etc.,
por supuesto sin saber cómo ocurría esto. Y su curiosidad aumentó, dando paso
a la investigación científica con avance en el conocimiento, y en paralelo, el
desarrollo tecnológico.
Pasaron los años y el conocimiento avanzó desde el exterior hacia el
interior de los organismos, llegando al nivel molecular.
Con el estudio de la manera de manejar la información por las células
se llegó a la posibilidad de manipular dicha información. Y surgió la
Ingeniería Genética, de la mano de la Biología Molecular, que no es más que
la Química de la Vida (Química Biológica) aplicada especialmente a los
procesos relacionados con el material genético y anexos.
Llegamos a la era del “Proyecto Genoma Humano”, con el desciframiento
completo de nuestra información genética. O casi completo, porque la actividad
dentro de nuestras células la lleva a cabo el conjunto de proteínas,
organizadas en caminos metabólicos, entrelazados entre sí dando lugar al
llamado “Metaboloma”.
Como ocurrió en los inicios de la actividad humana, el mayor
conocimiento de los sistemas llevó al deseo de mejorarlos, para que sirvieran
mejor a las necesidades de los individuos.
Y del “Proyecto Genoma” se pasó al “Proyecto Proteoma”, o “Genómica
Funcional”, visto que si la información contenida en el genoma no se expresa
en otras moléculas funcionales (por ejemplo: proteínas) de nada servirá. Y el
mejor conocimiento de la relación entre estructura, conformación espacial y
función llevó a ese deseo, desde el comienzo insertado en el ser humano, de
modificar la naturaleza para su bienestar, a querer rediseñar las proteínas,
modificando la actividad de las mismas.
Evolución, la adaptación gradual a una presión selectiva, es la manera
que tiene la naturaleza de responder a los variados desafíos ambientales. El
principio evolutivo puede describirse como ciclos repetidos de introducción de
mutaciones en el genoma, selección de fenotipos beneficiosos y pasaje de las
mutaciones seleccionadas a la descendencia, en forma directa (propagación
vegetativa) o vía recombinación genética con una pareja (propagación
sexual).
Los productos de una evolución Darwiniana son aparentes a todo nivel,
desde la impresionante diversidad en los organismos vivientes hasta las moléculas
proteicas individuales. Los científicos que desean rediseñar estas mismas moléculas,
están implementando su propia versión del algoritmo evolutivo. La llamada
“evolución dirigida” que nos permitirá explorar funciones enzimáticas no
requeridas por el medio ambiente natural y aquellas cuyas bases moleculares no
se comprenden en detalle.
En definitiva, podríamos decir que es una forma de modificar la evolución,
actuando directamente sobre las moléculas en cuestión, ya sea desde el
comienzo modificando la información genética o, a
posteriori, modificando directamente a la molécula de interés.
Si
se reconstruye la historia evolutiva de las proteínas actuales, aprendemos que
son moléculas altamente adaptables, al menos en la escala del tiempo evolutivo.
Muchas de las enzimas que catalizan reacciones diferentes han evolucionado en
forma divergente a partir de un ancestro común, adquiriendo capacidades muy
diversas por procesos de mutación al azar, recombinación y selección natural.
También sabemos que las enzimas que comparten una función común, por ejemplo,
catalizan un paso particular en un camino metabólico, además de su estructura
tridimensional pueden exhibir propiedades muy diferentes (estabilidad,
solubilidad, tolerancia a pH, etc.) dependiendo de dónde se las encuentre.
¿Por qué la
necesidad de una evolución dirigida?
Cuando
se utilizan enzimas naturales para una aplicación industrial, para servir como
catalizadores en síntesis químicas o como aditivos en detergentes de lavandería,
se descubre que no se adaptan bien para estas tareas. Debido a la poca
solubilidad del sustrato, ruptura de productos inestables o reacciones
competidoras, las condiciones para una reacción enzimática pueden no ser
apropiadas para una aplicación a gran escala.
Es posible producir nuevas enzimas en organismos recombinados, alterando
la secuencia de aminoácidos y, por lo tanto, las propiedades mediante
modificaciones apropiadas a nivel del ADN. Sin embargo, la experiencia demuestra
que los cambios en las propiedades enzimáticas provienen de la acumulación de
pequeños ajustes, muchos de los cuales están distribuidos a lo largo de
distancias significativas en la molécula.
La evolución es una herramienta poderosa con habilidad comprobada para
alterar la función enzimática y, especialmente, para ajustar las propiedades
enzimáticas. Es un algoritmo que puede ser implementado en el laboratorio para
rediseñar. El reto es comprimir la escala de tiempo a meses, o aún semanas.
A partir de este momento, pasamos a temas un poco más específicos y,
tal vez, algo más complicados. Espero que las figuras ayuden a comprender un
poco mejor estos conceptos.
¿Cómo hacer esto?
En estos momentos, tenemos a nuestro alcance oportunidades sin
precedentes para generar nuevas enzimas y biocatalizadores, utilizando técnicas
sofisticadas que mutan, recombinan y amplifican las secuencias de ácidos
nucleicos.
Un experimento típico de evolución dirigida comienza con la selección
de una biblioteca de secuencias de ADN parental que codificque para proteínas
que involucran, en parte, la propiedad buscada. La diversidad de secuencias
exploradas es, luego, incrementada mediante el paso de mutagénesis,
introduciendo mutaciones nucleotídicas puntuales al azar y/o por recombinación
de fragmentos de ADN. El paso de mutagénesis y fragmentación deja a todas, con
pocas excepciones, las secuencias inactivas. Estas secuencias de ADN son, luego,
ligadas a un vector de expresión y se transforman células de Escherichia
coli. Luego, se emplea un procedimiento de búsqueda (“screening”) para
aislar las pocas células transformadas que contienen las secuencias
codificantes para enzimas activas o proteínas funcionales. Estas secuencias
seleccionadas son, luego, amplificadas y se repite el ciclo de mutagénesis, búsqueda
y amplificación, múltiples veces, hasta que se encuentran las proteínas con
la función o propiedad deseadas.
Estrategias para las mutaciones.
La mutagénesis de un gen puede realizarse en forma diseminada a lo largo
de una secuencia o dirigida a una región en particular.
La primera puede lograrse mediante la llamada “PCR
con predisposición a errores” (“error-prone PR”) o mediante la tecnología
de “mezclado de ADN” (“DNA-shuffling”).
En la primera, el gen de interés es amplificado con una ADN polimerasa en condiciones donde la fidelidad transcripcional es baja y se introducen errores en las copias generadas. Dado que la mayoría de las mutaciones no son beneficiosas, dos mutaciones favorables se acumularán en el mismo gen, solamente con baja probabilidad y muchas mutaciones beneficiosas serán enmascaradas por las deletéreas. Para combinar varias mutaciones deseables, se utiliza un segundo método, donde el conjunto de fragmentos de ADN generado por la PCR es digerido por DNasa I, una enzima que corta en forma inespecífica, y se reensamblan los trozos por PCR. En principio, cada mutación puede ser recombinada y propagada individual e independientemente de otras mutaciones. Este proceso se asemeja al “crossing-over” que tiene lugar en los cromosomas de los organismos vivientes.
Para introducir mutaciones solamente en una región particular de un gen, puede utilizarse la mutagénesis en cassette por PCR. El fragmento de ADN conteniendo el punto mutado es recortado entre dos sitios de restricción flanqueantes. Luego, un producto de PCR, que puede ligarse exactamente en estos sitios de restricción, se genera con un cebador degenerado. Este iniciador se sintetiza químicamente para llevar una mezcla al azar de nucleótidos en uno o más codones y la proteína codificada lleva, por lo tanto, un conjunto de aminoácidos al azar, en esta posición particular. Desafortunadamente, un codón completamente formado al azar exhibirá una fuerte desviación hacia algunos aminoácidos que son codificados por más de un codón, por ejemplo, el aminoácido serina es codificado por seis codones diferentes, mientras que triptofano está codificado por un solo codón), siendo también difícil evitar la incorporación de un codón de terminación. La solución a este problema es usar trinucleótidos presintetizados (codones) para todos los 20 aminoácidos como bloques de construcción para la síntesis de ADN de los oligonucleótidos, en lugar de utilizar los mononucleótidos convencionales. Estos bloques pueden ser mezclados en cualquier proporción y solamente se necesita agregar aquellos trinucleótidos que el investigador desea en esta posición en la secuencia proteica.
 Figura 1.- Estrategias para mutagénesis,
con el fin de obtener las modificaciones localizadas o en genes enteros. En
el panel (A) se muestra en forma esquemática el proceso de PCR “sujeto a
error”, como una estrategia para la distribución no dirigida de mutaciones en
un gen de interés. Se muestran dos tipos de mutaciones, las favorables
(cuadrados) y las desfavorables (círculos). En ciclos sucesivos de PCR, se
introducen más mutaciones de cada tipo y, generalmente, las moléculas contendrán
alguna de cualquier tipo. Así, el efecto benéfico de las mutaciones favorables
puede ser opacado, completamente, por la presencia de las desfavorables. Una
posible solución a este problema, se muestra en el panel (B) y se conoce como
“mezclado de ADN”. El producto de PCR se corta en pequeños trozos,
utilizando la enzima ADNasa I y se reensamblan, subsecuentemente, mediante PCR.
Las mutaciones quedan, por lo tanto, cruzadas y los genes con el mayor número
de mutaciones favorables pueden ser enriquecido por selección. El panel (C)
muestra el principio de PCR utilizando un “primer degenerado”. Este “primer”
o iniciador contiene una mezcla de todos los cuatro posibles nucleótidos
(abreviados en la letra N) en una posición determinada o, alternativamente, una
mezcla de codones ensamblados a partir de trinucleótidos. Las proteínas
sintetizadas a partir de este gen llevarán, por lo tanto, un grupo “randomizado”
de aminoácidos en esta posición. Ver Figura
1 tamaño completo
Figura 1.- Estrategias para mutagénesis,
con el fin de obtener las modificaciones localizadas o en genes enteros. En
el panel (A) se muestra en forma esquemática el proceso de PCR “sujeto a
error”, como una estrategia para la distribución no dirigida de mutaciones en
un gen de interés. Se muestran dos tipos de mutaciones, las favorables
(cuadrados) y las desfavorables (círculos). En ciclos sucesivos de PCR, se
introducen más mutaciones de cada tipo y, generalmente, las moléculas contendrán
alguna de cualquier tipo. Así, el efecto benéfico de las mutaciones favorables
puede ser opacado, completamente, por la presencia de las desfavorables. Una
posible solución a este problema, se muestra en el panel (B) y se conoce como
“mezclado de ADN”. El producto de PCR se corta en pequeños trozos,
utilizando la enzima ADNasa I y se reensamblan, subsecuentemente, mediante PCR.
Las mutaciones quedan, por lo tanto, cruzadas y los genes con el mayor número
de mutaciones favorables pueden ser enriquecido por selección. El panel (C)
muestra el principio de PCR utilizando un “primer degenerado”. Este “primer”
o iniciador contiene una mezcla de todos los cuatro posibles nucleótidos
(abreviados en la letra N) en una posición determinada o, alternativamente, una
mezcla de codones ensamblados a partir de trinucleótidos. Las proteínas
sintetizadas a partir de este gen llevarán, por lo tanto, un grupo “randomizado”
de aminoácidos en esta posición. Ver Figura
1 tamaño completo
Estrategias para seleccionar las proteínas.
a)
“Display” ribosomal:
Se
transcribe una biblioteca de ADN, in vitro,
a ARN mensajero utilizando ARN polimerasa. Esta biblioteca de ARN mensajero
puede traducirse a proteína, utilizando la maquinaria bacteriana (extracto
bacteriano S30). Luego de detener la traducción por enfriamiento y aumentando
la concentración de magnesio, el ARN mensajero (ARNm), el ribosoma y la proteína
recién sintetizada formarán un complejo ternario. Los complejos ribosomales
deseados se seleccionan por afinidad, de la mezcla de traducción, por unión de
la proteína nativa al antígeno inmovilizado. Los complejos ribosomales no
específicos se eliminan por lavado exhaustivo. Los complejos ribosomales unidos
se eluyen con antígeno y se puede recuperar el ARNm y transcribirlo en forma
reversa obteniendo cADN (ADN copia) mediante la técnica de RT-PCR. Este cADN
puede utilizarse en el próximo ciclo de enriquecimiento o puede analizarse por
secuenciación.
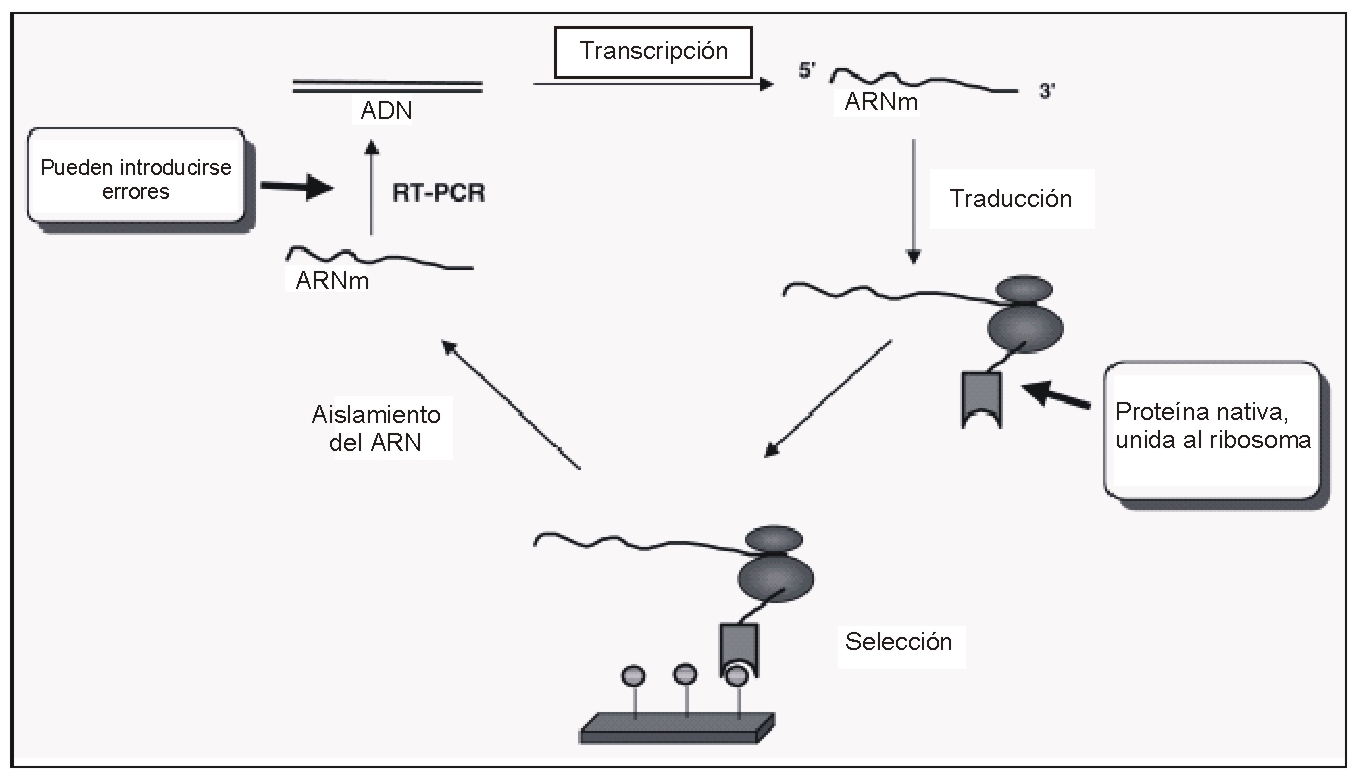
Figura 2.- Principio de búsqueda y selección de una proteína ligadora,
a partir de una biblioteca de ADN, utilizando la tecnología del “display”
ribosomal.
b)
Ensayo de complementación de fragmentos proteicos (PCA), para la selección
simultánea de interacciones proteína/proteína.
En
este método, una biblioteca proteica puede ser analizada contra otra biblioteca
proteica. Esto es útil para obtener un mapa de proteínas interactuantes dentro
de un organismo pero también, para identificar ligandos de una biblioteca de
anticuerpos.
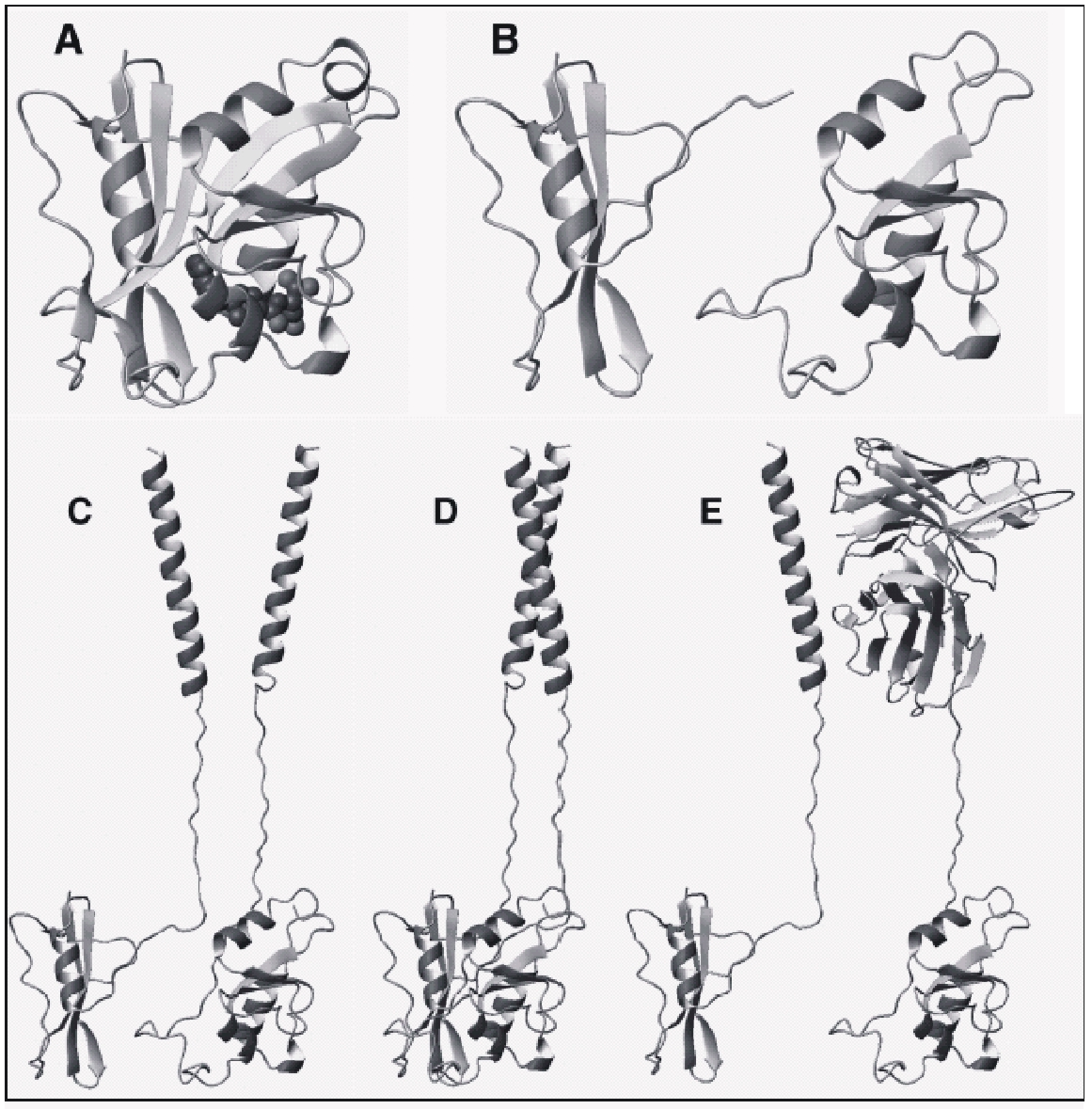
Figura 3.- Principio del ensayo de
complementación de fragmentos proteicos: (A) Enzima dihidrofolato reductasa
murina (DHFR), nativa, mostrada como diagrama de “cinta”. Esta enzima es
importante para la biosíntesis de purinas, timidilato, metionina y pantotenato.
En esta figura, también se muestra al cofactor folato, en un modelo espacial.
Si esta enzima se parte, genéticamente, en dos (B), los fragmentos no se
reasociarán y se perderá la actividad. Por lo tanto, se impide la división y
el crecimiento celular en un medio mínimo. La fusión de los fragmentos
individuales a dominios proteicos, formando un complejo (C) puede dirigir el
reensamblado de los fragmentos de DHFR, recuperándose la actividad (D). Este
sistema se utiliza, en la actualidad, para seleccionar anticuerpos scFv, a
partir de una biblioteca de ADN, contra “blancos” definidos, fusionados a un
fragmento de la DHFR (E).
Ver
Figura
3 tamaño completo
Existen cuatro requerimientos para una evolución dirigida exitosa: 1) la
función deseada debe ser físicamente posible, 2) la función debe ser, también,
biológica o evolutivamente posible, 3) también debe ser posible obtener
bibliotecas de mutantes, lo suficientemente complejas como para contener
mutaciones beneficiosas y, 4) debe existir una forma rápida de seguimiento o
selección que refleje la función deseada.
Recientemente se ha obtenido un gran éxito en la obtención de enzimas
con utilidad industrial, con una mejora sustancial en la actividad y
termoestabilidad, como así también
de vacunas y productos farmacéuticos.
Cada vez cobra más realidad la afirmación: “el hombre se ha
convertido en la primera criatura de la evolución, capaz de modificar la
evolución”. El futuro dirá hasta dónde se podrán diseñar proteínas “a
medida” de las necesidades que vayan surgiendo.
Por ahora, nos encontramos como nuestro antecesor prehistórico:
asombrados ante la enorme vastedad de posibilidades y dispuestos a escribir un
nuevo capítulo en la historia de los avances científicos.
Solamente resta esperar que todo sea para bien.
Bibliografía consultada:
-Modelling DNA mutation and recombination for directed evolution experiments. Gregory L. Moore and Costas D. Maranas J. theor. Biol. (2000) 205: 483-503
-Directed evolution with fast and efficient selection technologies. Ekkehard Mössner and Andreas Plückthun Chimia (2001) 55: 324-328
-http://www.che.caltech.edu/groups/fha/Enzyme/directed.html
Directed enzyme evolution. Frances
H. Arnold.
|
ISSN 1666-7948 www.quimicaviva.qb.fcen.uba.ar |